![]()
Préambule¶
Federa est un Data Lake permettant à ses utilisateurs de créer rapidement des systèmes d'aide à la décision.
Federa offre toutes les fonctionnalités d'un Data Lake traditionnel telles que le stockage et le traitement de quantités massives de données hétérogènes, à la fois structurées et non structurées. Cependant, Federa est unique : au lieu de stocker les données sous formes de blobs ou de fichiers, Federa inspecte et extrait automatiquement le contenu de plus d'une trentaine de formats de fichiers (dont PDF, Word, PowerPoint, CSV, etc.) Les données extraites sont ensuite sauvegardées sous forme d'enregistrements individuels regroupés logiquement en jeux de données.
Federa a été spécialement conçu pour se conformer aux exigences de confidentialité du GDPR et du CCPA.
Aperçu du fonctionnement de la plateforme¶
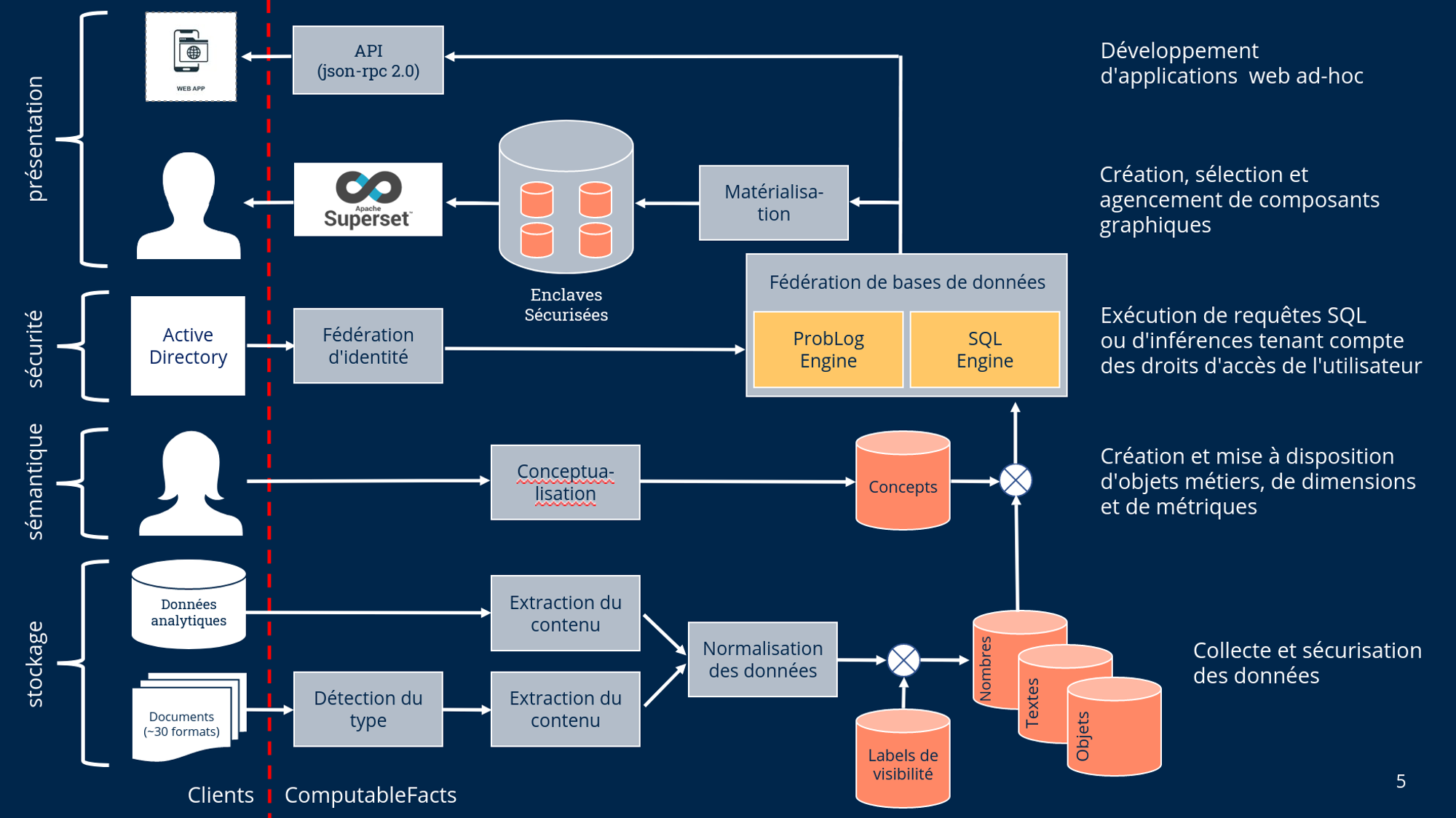
Capture & Stockage¶
Les données provenant de sources internes et/ou externes sont capturées puis stockées dans des systèmes appropriés pour un traitement ultérieur. L'objectif est d'identifier, d'acquérir et de stocker les données pertinentes issues du système d'information de l'organisation, de bases de données opérationnelles ou de sources externes (ex. Open Data).
Sémantique¶
Les données passent par une série d'opérations de prétraitement afin d'être qualifiées, nettoyées et structurées de manière à en faciliter la réutilisation. La notion de concept a pour but de généraliser et d'harmoniser les différentes manières dont les utilisateurs accèdent aux données. L'objectif est de mettre en relations les données d'une part et les concepts métiers d'autre part afin de fournir à tous les utilisateurs une compréhension unifiée des données. Cette mise en relation constitue un atout important pour l'organisation en établissant un vocabulaire commun garantissant sa cohésion.
Sécurité¶
Chaque donnée intégrée dans Federa peut être associée à une étiquette de sécurité. Cette étiquette de sécurité est utilisée pour déterminer si un utilisateur répond aux exigences de sécurité requis pour accéder à une donnée. Cela permet à la fois de stocker des données nécessitant différents niveaux d'habilitation au sein d'un même système mais aussi à des utilisateurs possédant différents niveaux d'habilitation d'interroger ce même système tout en préservant la confidentialité des données.
Présentation¶
Les modules sont des applications Web évolutives (UI ou API) permettant de répondre à une ou plusieurs questions analytiques précises.
Modules de type UI¶
Un Module de type UI est une application Web stateless utilisant notre SDK Javascript pour communiquer avec la plateforme. Un Module de type UI permet, par exemple, d’agencer librement des composants graphiques.
- L’application Web est versionnée par git et déployée à l’aide de Jenkins dans notre infrastructure.
- L’application Web est accessible aux utilisateurs via l’entrée de menu « Modules » de la plateforme.
- Le SDK Javascript propage de manière transparente l’identité, les permissions et les autorisations de l’utilisateur au Module.
Modules de type API¶
Un Module de type API est une API Python stateless réalisée à l’aide de FastAPI. Un Module de type API permet, par exemple, de réaliser des calculs complexes qu’il serait peu aisé d’implanter en Javascript.
- L’API est versionnée par
gitet déployée à l’aide de Jenkins dans notre infrastructure. - L’API est accessible par n’importe quel Module de type UI.
- L’identité, les permissions et les autorisations de l’utilisateur sont transmis à l’API par le paramètre
api_keyajouté à l’URL par le SDK d’un Module de type UI.
Autres interfaces¶
La plateforme s’interface avec les outils de visualisation suivants :
- Microsoft Excel (au moyen d’une API REST)
- Microsoft Power BI Desktop (au moyen d’une API REST ou d’un driver ODBC)
- Microsoft Power BI 360 (au moyen d’une API REST)
- Apache Superset (nativement)